jump to...
Your Retrieval System Needs Three Layers. Most Have One.

Last month I argued that single-shot retrieval is dead and agentic search is what replaces it. That post drew a line between “search and hope” and “search, reason, search again.” But I left out the how. This is the how.
If you read Your RAG Pipeline Isn’t Searching. It’s Pattern Matching, you already know the progression: vector search alone misses exact matches, hybrid search fixes recall but is still a single shot, and agentic search lets the LLM drive the retrieval process. I ended that post by saying the future is convergence: agents using hybrid search as one tool among several.
I’ve spent the weeks since digging into the research that’s come out in early 2026, and the picture is sharper now. The teams building production-grade retrieval systems aren’t just “adding agents on top of RAG.” They’re building a specific three-layer architecture, and each layer exists for a reason.
Layer 1: Hybrid Retrieval as Infrastructure
I covered hybrid search in the first post, but there’s a piece I skipped. The stack is evolving past two signals.
Everyone knows the BM25 + vector + reranker pattern by now. What’s emerging is a third retrieval signal: knowledge graphs. Microsoft open-sourced GraphRAG in mid-2024, and it filled a gap that keyword and semantic search can’t touch. Ask a hybrid system “what themes emerge across these 500 customer support tickets?” and you’ll get individual tickets that match your query terms or meaning. You won’t get the thematic summary, because that requires understanding relationships between entities across documents, not similarity to a query.
GraphRAG builds an entity-relationship graph over your corpus. Entities get extracted, relationships get mapped, and the graph enables queries like “which customers are connected to this product line through support escalations in Q3?” The kind of structural question that neither BM25 nor embeddings were designed for. LightRAG strips out the community detection overhead from Microsoft’s approach to make it more production-friendly.
Some practitioners are calling the combination Tri-Modal Hybrid RAG: BM25 for exactness, vectors for meaning, GraphRAG for relationships, with a reranker for final precision. Each signal covers a blind spot the others have. And production benchmarks show that even with all three signals plus reranking, you’re still under 700ms at 10 million documents. That’s within acceptable latency for most enterprise use cases.
One thing I want to stress because I keep seeing teams get this wrong: the sequencing matters. A reranker can only reorder documents that were already retrieved. If your recall is poor, if the relevant documents aren’t even in the candidate set, no amount of reranking fixes it. Fix recall first (that’s what adding BM25 and graph retrieval does), then add the reranker for precision. I’ve seen teams burn months tuning reranker models when their actual problem was at the retrieval layer.
This is Layer 1. Fast, explainable, multi-signal retrieval. It’s the engine. But it’s not the driver.
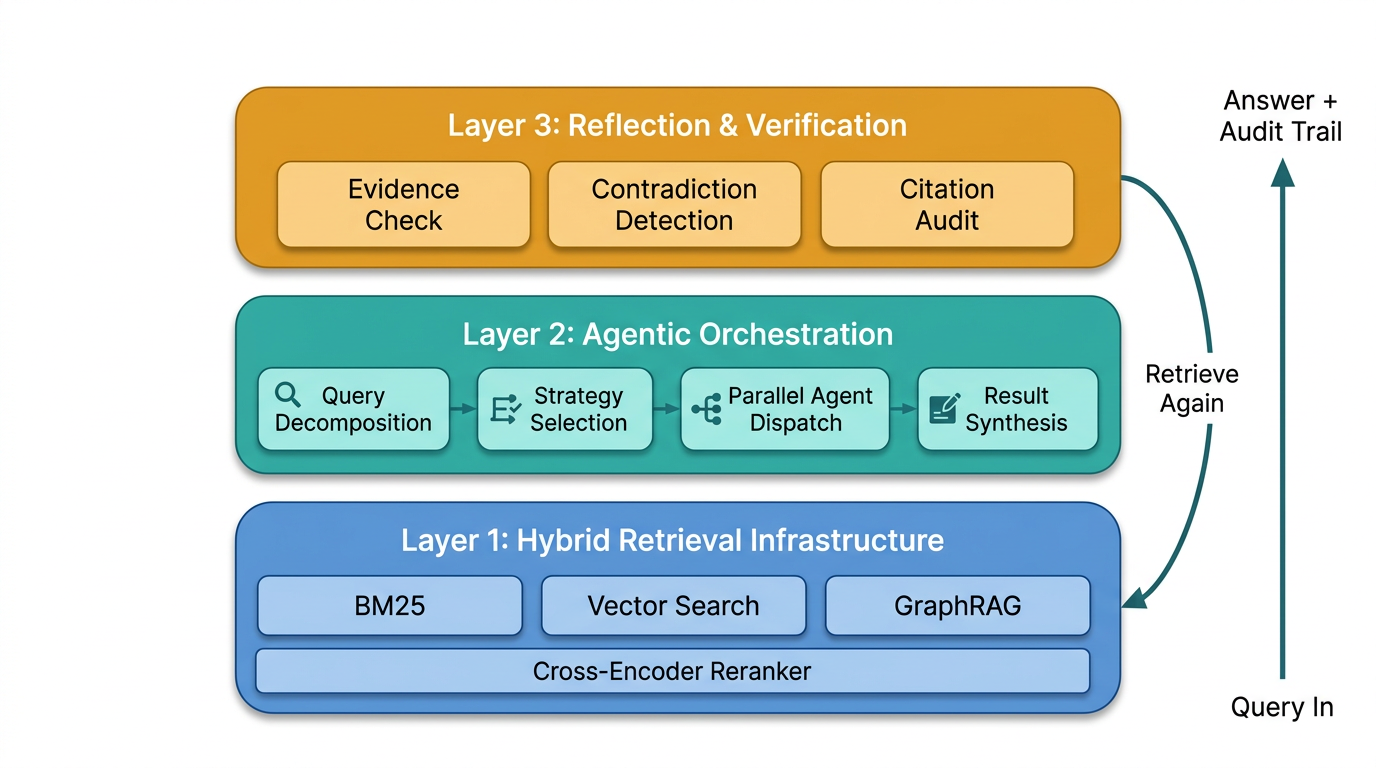
Layer 2: Agentic Orchestration
In the first post I described agentic search as “the LLM driving the retrieval.” That’s true, but it’s vague. The research that’s come out since paints a much more specific picture of what that looks like in practice.
A January 2025 survey by Singh et al. mapped the full taxonomy of what they formally call Agentic RAG: systems where autonomous agents are embedded directly into the retrieval pipeline. They identified four design patterns that layer on top of each other: reflection, planning, tool use, and multi-agent collaboration.
Planning is the one that changes everything. Instead of the user’s question going straight to a search function, it goes to an LLM that decomposes the question first.
A May 2025 paper by Nguyen et al. describes MA-RAG, a system with four specialized agents: a Planner that breaks the query into sub-tasks, a Step Definer that sequences them, an Extractor that handles the actual retrieval, and a QA agent that synthesizes the final answer. Each agent communicates intermediate reasoning via chain-of-thought prompting. On multi-hop question-answering benchmarks (HotpotQA, 2WikimQA), this approach significantly outperformed both standalone LLMs and traditional RAG across all model sizes they tested.
Here’s a concrete example of why decomposition matters. Say you’re a B2B sales organization trying to identify accounts where a vendor relationship was established without your team’s awareness. A single-shot system, even a good hybrid one, searches for what you asked and returns whatever matches. An agentic system decomposes it: one agent searches public earnings reports and press releases for deal announcements. Another agent searches your CRM for pipeline activity in those same accounts. A third agent checks timing correlations. Each agent brings back partial results. The orchestrator synthesizes the gaps.
No single search would have found that. The intelligence is in the decomposition.
But what really caught my attention is the A-RAG paper from February 2026. They took a different angle on the same problem. Instead of specializing agents by role (planner, extractor, etc.), they specialized by retrieval granularity. Their system exposes three tools to the model: keyword search, semantic search, and chunk read. The agent decides at each step which tool to use.
Their ablation studies are what convinced me this matters. Removing either keyword or semantic search degraded performance, confirming that multi-granularity access isn’t just nice to have. And the progressive acquisition design, where the agent reads summaries first, then selectively reads full chunks only when needed, reduced total tokens retrieved while improving accuracy. The agent wasn’t just searching better. It was searching more efficiently by choosing the right tool for each step.
This is the insight I missed in my first post. I framed agentic search as “the LLM searches multiple times.” The better framing is: the LLM chooses how to search each time. That’s a fundamentally different capability. It’s the difference between a developer who runs the same grep five times with different terms and a developer who switches between grep, a database query, and reading the actual source file depending on what they’re looking for.
Layer 3: Reflection and Verification
This is the layer nobody had in 2024, and it’s the one that makes the whole thing production-viable for enterprise.
After the orchestration layer has planned, searched, and synthesized, the reflection layer asks: is this good enough? Did we find sufficient evidence? Are there contradictions across sources? Should we retrieve again with a different strategy? And critically for enterprises: can we trace every claim back to a source document?
The Data Nucleus enterprise deployment guide (January 2026) formalizes this as a plan-retrieve-act-reflect-answer cycle. Plan by breaking the task into steps. Retrieve using hybrid search with reranking. Act by calling tools: parsers, calculators, database lookups. Reflect by self-checking and deciding whether another retrieval pass is needed. Answer with citations and an audit trail.
That audit trail piece matters more than most technical teams realize. I talk to enterprise leaders regularly, and “the model said so” doesn’t fly. Regulators, auditors, and internal governance teams need to trace every claim back to its source. Agentic RAG makes this possible because every retrieval step is logged, every agent decision is recorded, and every synthesis step can be inspected. The reflection layer is what produces that trail.
Self-RAG, one of the approaches referenced in the Singh survey, trains models to decide when to retrieve and to critique their own outputs. The model generates an answer, evaluates whether it needs more evidence, and either retrieves again or outputs with citations. This improves factuality and citation accuracy. It sounds incremental, but for compliance-heavy industries it’s the difference between “useful experiment” and “deployable system.”
The enterprise-specific guidance from Data Nucleus also recommends ReAct-style prompting for this layer: the agent thinks, acts (searches), observes the results, and thinks again. For empty or vague queries, they suggest HyDE (Hypothetical Document Embeddings). The system generates a hypothetical answer first, embeds that, and retrieves real documents similar to the hypothesis. It sounds circular, but it solves the cold-start problem for queries where the user doesn’t know the right terminology to trigger effective retrieval.
Without the reflection layer, you have a system that searches multiple times but can’t evaluate its own work. With it, you have a system that knows when it doesn’t know enough. That’s the gap.
Scaling: Breadth, Not Just Depth
One more piece of research that changed how I think about this.
A February 2026 paper called WideSeek proposes what they call “Wide Research,” a shift from deep sequential reasoning to parallelized search across expansive search spaces. The standard pattern in multi-agent systems is depth: break a question into steps, execute them sequentially, go deeper at each step. WideSeek argues that some questions don’t need deeper reasoning. They need wider coverage.
Their architecture uses a hierarchical multi-agent system where an orchestrator decomposes objectives into parallel sub-tasks, each executed by autonomous agents that can cross-validate each other’s findings. Optimized through reinforcement learning, the system learns to allocate agents efficiently across broad search spaces.
This is a different mental model than what I described in my first post. I talked about an agent doing “five or six retrieval steps instead of one.” WideSeek is doing twenty retrieval steps simultaneously, with different agents covering different regions of the search space, then synthesizing. It’s the difference between one analyst doing serial searches and a team of analysts each covering a different angle and comparing notes.
On the production side, a February 2026 write-up from Oracle’s engineering team shows how this scales mechanically. They allocate independent compute per agent type: planner agents on one cluster, researcher agents on another, synthesis agents on a third. When query volume spikes, you scale the researcher cluster without touching planner infrastructure. They’re using Google’s Agent2Agent (A2A) protocol, an open standard for inter-agent communication, so each agent is an independently deployable service.
This solves the throughput problem that I hand-waved in my first post when I said agentic search is slow. Yes, a serial agentic pipeline is slow. A parallelized multi-agent system with independent scaling? That’s a different equation.
Where This Still Breaks
I don’t want to oversell this. There are real problems.
Cost hasn’t been solved. A complex query triggering 15-20 LLM calls at current API pricing adds up. Semantic caching helps (store query-result pairs so repeated or similar queries skip the full pipeline), and model tiering helps (use smaller models for retrieval planning, larger ones for synthesis). But for high-volume workloads, the economics still favor single-shot hybrid search for simple queries. The right system uses agents selectively. Let the orchestrator decide “this is a straightforward lookup, skip the multi-agent pipeline.”
Coordination is hard. Agents can loop infinitely if the reflection step never concludes it has enough. They can return conflicting results the synthesizer can’t reconcile. Frameworks like LangGraph, LlamaIndex agents, CrewAI, and Microsoft AutoGen are maturing, but the debugging tooling lags behind the architecture complexity. When your system is three agents deep and producing a wrong answer, figuring out which agent failed and why is still painful.
The orchestrator can hallucinate search strategies. The planner itself is an LLM. It can invent retrieval steps that sound reasonable but target data that doesn’t exist. “Search for the customer’s earnings report” when no such document is in the corpus. Guard rails at the tool level, returning explicit “no results found” rather than empty strings, help, but this is an active area of research with no clean solution yet.
What Changed Since My First Post
If I’m being honest, my first post framed this as a spectrum. RAG on one end, agentic search on the other, hybrid in the middle. Pick your spot based on your use case. That’s not wrong, but it misses the architectural insight.
The better framing is layers. You don’t choose between hybrid and agentic. You build hybrid as your foundation, agentic orchestration as the intelligence that uses it, and reflection as the quality control that validates it. Simple queries hit Layer 1 and return fast. Complex queries engage all three layers. The orchestrator is the one making that decision, not the developer at design time.
The research from the last few months has made me more confident about something else, too. The industry is converging on this pattern. A-RAG’s hierarchical tool selection, MA-RAG’s multi-agent decomposition, WideSeek’s parallel search paradigm. These are different teams arriving at the same conclusion from different directions. That usually means the pattern is real.
If you built a hybrid search system after my first post, good. That’s Layer 1 and it’s solid. The next step is adding an orchestration layer that can decompose queries and choose retrieval strategies dynamically. Start simple: a single agent that breaks questions into sub-queries and runs hybrid search for each. You’ll see the improvement on your complex queries immediately.
Layer 3, the reflection loop, is what you add when the stakes are high enough that “the system needs to know when it doesn’t know enough” becomes a requirement. For most teams, that’s the next twelve months.
The retrieval layer isn’t just getting smarter. It’s becoming a system.
References
[1] Singh, A. et al. (2025). “Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG.” arXiv:2501.09136. https://arxiv.org/abs/2501.09136
[2] Nguyen, T. et al. (2025). “MA-RAG: Multi-Agent Retrieval-Augmented Generation via Collaborative Chain-of-Thought Reasoning.” arXiv:2505.20096. https://arxiv.org/abs/2505.20096
[3] A-RAG (2026). “A-RAG: Scaling Agentic Retrieval-Augmented Generation via Hierarchical Retrieval Interfaces.” arXiv:2602.03442. https://arxiv.org/html/2602.03442v1
[4] WideSeek (2026). “WideSeek: Advancing Wide Research via Multi-Agent Scaling.” arXiv:2602.02636. https://arxiv.org/html/2602.02636
[5] Martinez, N. (2026). “Build a Scalable Multi Agent RAG system with A2A Protocol and LangChain.” Oracle Developers Blog. https://blogs.oracle.com/developers/build-a-scalable-multi-agent-rag-system-with-a2a-protocol-and-langchain
[6] Data Nucleus (2026). “Agentic RAG in 2026: The UK/EU Enterprise Guide to Grounded GenAI.” https://datanucleus.dev/rag-and-agentic-ai/agentic-rag-enterprise-guide-2026
[7] NetApp Community (2026). “Hybrid RAG in the Real World: Graphs, BM25, and the End of Black-Box Retrieval.” https://community.netapp.com/t5/Tech-ONTAP-Blogs/Hybrid-RAG-in-the-Real-World-Graphs-BM25-and-the-End-of-Black-Box-Retrieval/ba-p/464834
[8] Prem AI (2026). “Hybrid Search for RAG: BM25, SPLADE, and Vector Search Combined.” https://blog.premai.io/hybrid-search-for-rag-bm25-splade-and-vector-search-combined/
[9] RAGFlow (2024). “The Rise and Evolution of RAG in 2024: A Year in Review.” https://ragflow.io/blog/the-rise-and-evolution-of-rag-in-2024-a-year-in-review
[10] IBM (2025). “What is Agentic RAG?” https://www.ibm.com/think/topics/agentic-rag
[11] Glean (2026). “Agentic RAG Explained: Smarter Retrieval with AI Agents.” https://www.glean.com/blog/agentic-rag-explained
[12] LlamaIndex. “Agentic Retrieval Guide: Beyond Naive RAG.” https://www.llamaindex.ai/blog/rag-is-dead-long-live-agentic-retrieval
[13] Singh, A.P. et al. (2025). “Agentic Retrieval-Augmented Generation: Advancing AI-Driven Information Retrieval and Processing.” IJCTT, Vol. 73, Issue 1, pp. 91-97. https://www.ijcttjournal.org/2025/Volume-73%20Issue-1/IJCTT-V73I1P111.pdf
[14] MMA-RAG (2025). “MMA-RAG: A Survey on Multimodal Agentic Retrieval-Augmented Generation.” HAL Archives. https://hal.science/hal-05322313v1/document
Daron Yondem advises senior technology leaders on AI-driven organizational transformation. Learn more →