jump to...
Analyzing Large Documents With Azure Text Analytics
A day ago, I saw Anuraj, a fellow MVP, researching the document size limitations of Azure Text Analytics. If you look at the official documentation, the answer is pretty straightforward, and in some sense, not so helpful.
Looking into the problem, I realized one of the best and low-cost solutions is to build a project around Azure Durable Functions. We can have a Durable Functions Orchestrator that can split the text, pass the segments to Text Analytics with a fan-out, combine the results to make sure we don’t get duplicate keywords received from all text segments. Let’s do it :)
Splitting the Text File
The first step is to split the text file into smaller segments. As my sample text file, I will use the plain text version of “A Century of Parody and Imitation” by Walter Jerrold and R. M. Leonard from the Gutenberg Project. We will create an HTTP function that gets the text file’s direct URL and splits it into digestible segments for TextAnalytics.
[FunctionName("Analyze")]
public static async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", Route = null)]
HttpRequest req,
[DurableClient] IDurableOrchestrationClient starter,
ILogger log)
{
//Test Sample: http://www.gutenberg.org/files/64229/64229-0.txt
//724 kB plain text version of "A Century of Parody and Imitation"
//by Walter Jerrold and R. M. Leonard
string textFileUrl = req.Query["documentUrl"];
WebClient webClient = new WebClient();
string textContent = webClient.DownloadString(textFileUrl);
string[] lines = textContent.Split(
new[] { "\r\n", "\r", "\n" },
StringSplitOptions.None
);
var textSegments = new List<string>();
var lineIndex = 0;
while (lineIndex < lines.Length)
{
StringBuilder sb = new StringBuilder();
while (sb.Length < 5000 && lineIndex < lines.Length)
{
sb.Append(lines[lineIndex]);
lineIndex += 1;
}
textSegments.Add(sb.ToString());
}
string instanceId = await starter.StartNewAsync(
"TextAnalyticsOrchestrator",
input: textSegments.ToArray());
return starter.CreateCheckStatusResponse(req, instanceId);
}
First, I’m splitting the files into separate lines hoping that line separation will help keeping sentence structure and meaning as much as possible before I cut the text into 5000 character length segments. The maximum size for a single document for Text Analytics is 5,120 characters. I could have implemented the splitting as an asynchronous task and orchestrated it with Durable Functions. In this case, I wanted this process to be part of the initial HTTP request to make sure failure in segmentation is something the user can face during document submission, the initial GET request. This is not a very good idea if your files are massive :) I will talk about the gigantic files scenario later on.
Orchestration and Fan-Out
starter.StartNewAsync is where we are starting our Durable Functions orchestrator. As a reminder, you have to add Durable Functions nuget package to be able to use the functionality with Azure Functions. Our orchestrator name is TextAnalyticsOrchestrator and we are passing the list of segments we have created as a parameter.
[FunctionName("TextAnalyticsOrchestrator")]
public static async Task<HashSet<string>> RunOrchestrator(
[OrchestrationTrigger] IDurableOrchestrationContext context)
{
var textSegments = context.GetInput<string[]>();
var outputs = new List<Task<HashSet<string>>>();
foreach (var textSegment in textSegments)
{
outputs.Add(
context.CallActivityAsync<HashSet<string>>(
"AnalyzeText", textSegment));
}
await Task.WhenAll(outputs);
HashSet<string> finalKeyPhrases = new HashSet<string>();
foreach (var outputHashSet in outputs.Select(x => x.Result))
{
finalKeyPhrases.UnionWith(outputHashSet);
}
return finalKeyPhrases;
}
The Orchestrator gets the list of segments and is supposed to start the AnalyzeText activity function for every segment in an asynchronous fashion. You can see the loop that is calling CallActivityAsync to start a new instance of AnalyzeText for each text segment. Those are async calls where we get back a Task that we put in our list of tasks outputs to wait until we can continue. Once all the tasks are completed, we join the HashSets we have and call it a day. At this point, based on your needs I suggest adding another activity to save the output to a location that makes sense for you.
[FunctionName("AnalyzeText")]
public static HashSet<string> AnalyzeText([ActivityTrigger] string text,
ILogger log)
{
string textAnalyticsKey =
Environment.GetEnvironmentVariable("TextAnalyticsKey");
string textAnalyticsEndpoint =
Environment.GetEnvironmentVariable("TextAnalyticsEndpoint");
var keyPhrases = new HashSet<string>();
var client = new TextAnalyticsClient(new Uri(textAnalyticsEndpoint),
new AzureKeyCredential(textAnalyticsKey));
var response = client.ExtractKeyPhrases(text);
foreach (string keyphrase in response.Value)
{
keyPhrases.Add(keyphrase);
}
return keyPhrases;
}
Our AnalyzeText activity does only one thing; it runs the segment through Text Analytics and returns the list of keyphrases. This is the function that will be called thousands of times based on the number of segments you have based on the size of the initial document.
The Architecture
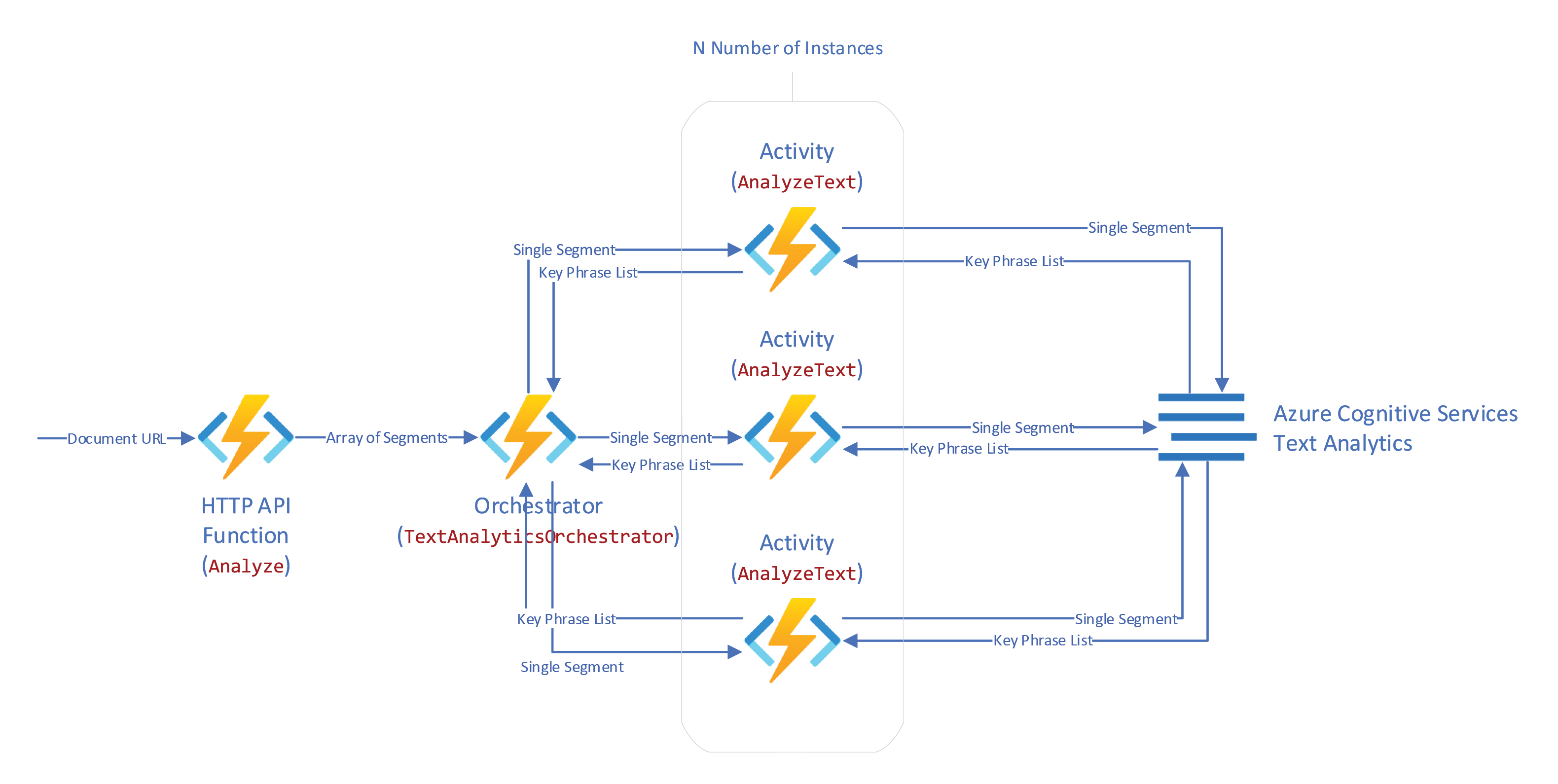
In case you are not familiar with Durable Functions, here is what will happen next. With every HTTP request coming in, we will have a new document to analyze. The document will be split into N number of segments, and the list will be handed off to the orchestrator function. At this point, the HTTP function will fade and return a response to the user with a couple of links to check the orchestrator’s status or a link to kill it. The orchestrator will run in a separate function independently and asynchronously. The orchestrator will spin up N number of instances of the activity function that takes a segment of text and talks to Text Analytics services for Key Phrase analysis. Based on the number of tasks and the burn rate, the runtime will decide how far to fan out the underlying infrastructure. As long as the orchestrator has more jobs, the underlying infrastructure will scale to accommodate the needs. Once all tasks are completed, the orchestrator will resume to merge the results and hand them over. In our case, I did not implement logic to save the results in a remote location. I returned the output straight to Durable Functions to be stored as part of the result that can be queried through the link we received in the original HTTP request. This is not the best practice. You should save the output somewhere else and return only a small metadata that makes sense to save as part of the orchestrator’s result.
The Result
When you upload the solution to Azure, make sure you have Standard tier Text Analytics services. The free version has a 200 transaction/minute limit on it. The standard tier can go up to 1000 requests per minute.
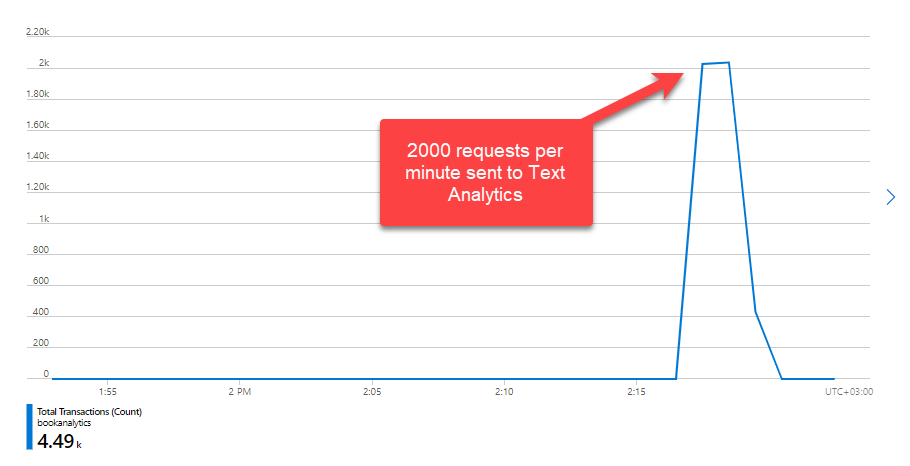
The above chart is not the result of a single document’s analysis. If I did not miss anything, I remember submitting ten different, pretty large documents. Text Analytics reports 2000 requests per minute received, but successful calls are just 1000 requests per minute, see the chart below.
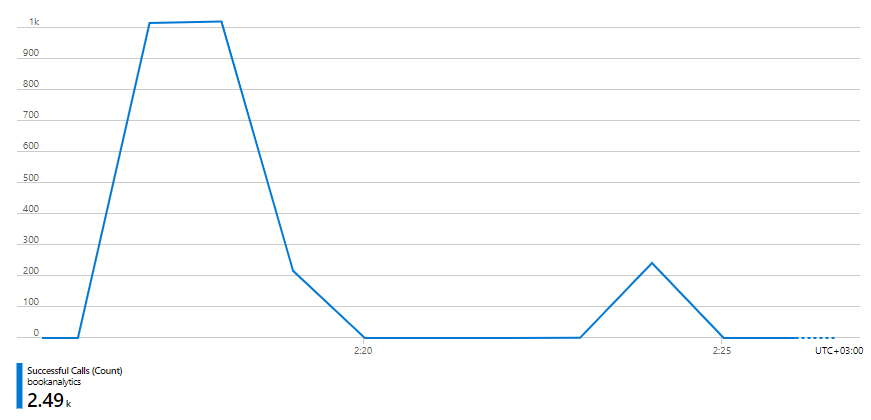
It looks like our Function app scaled more than Text Analytics could handle. It might be a good idea to throttle our implementation.
When you build Durable Functions solutions, it is crucial to make sure the Orchestrator does only orchestration. That is because the runtime will snapshot and replay the function. When your Orchestrator waits for all the activity tasks to be completed, it is unloaded, snapshotted, and its state is stored. When tasks are completed, the Orchestrator resumes from the beginning, plays back to where tasks are, and restores the results. Everything other than tasks have to run again during every playback. If you do a lot of heavy lifting in the Orchestrator itself, it will cost you cpu time and money.
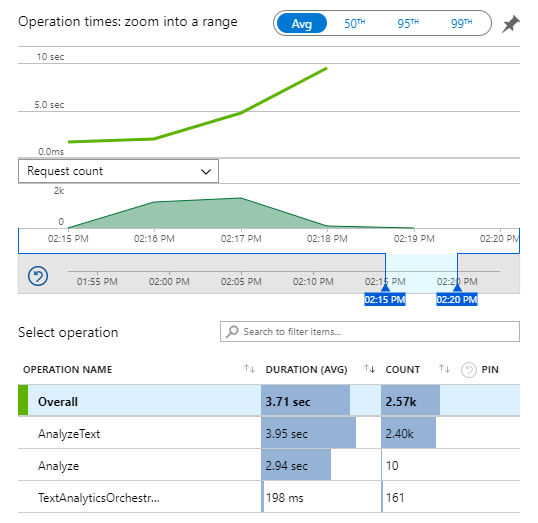
Looking at the chart above, it seems like we did a good job keeping the heavy lifting out of the orchestrator, even though we merged the HashSet in the orchestrator itself. Thankfully, that was at the end of the orchestrator function code, and it will never be replayed as there are no further tasks to orchestrate from that point forward.
The average runtime for the Orchestrator is just 198ms. That’s perfect. The timing for the two other functions looks good as well. However, something is interesting with the execution counts.
AnalyzeText ran 2.4K times. That’s ok. It looks like we successfully analyzed 2.4K segments. The number is aligned with the number of successful Text Analytics transactions we saw previously. The Analyze function is the HTTP function. It ran ten times. That approves my memory of submitting ten documents as a test. Finally, our Orchestrator ran 161 times. What?
Here is what we know so far; we run an orchestrator every time we run the HTTP function. That means we should at least have ten runs of the Orchestrator. We have 161. Oh wait, after we wait for all the tasks to complete, there is a replay. That counts as execution as well. Cool, we are up to two times ten equals 20. We are still 141 far. That’s because when there are tons of tasks to be waited and replays to be processed, Durable Functions Runtime does batch replays without waiting for all tasks to complete. There is a detailed section in the official docs about replays if interested :)
What Can Be Improved?
There are various ways the implementation can be improved. One of the problems is the large array passed to the Orchestrator during initialization. Instead of keeping the segments in memory, each segment can be saved to a blob with a prefix that can be queried by the Orchestrator to create all the tasks. Additionally, instead of passing the full payload for the segment, identifiers can be passed around till the final TextAnalytics activity has to fetch the text from the matching blob.
Another potential issue might be the initial loading of the file by the HTTP Function. Currently, the function is downloading the full file into memory to split it. Instead of a batch read, a streaming approach can keep reading the incoming stream and create segments while at it. Incoming segments can be analyzed without waiting for each other. The only operation that has to wait for all segments to be completed is the final join of all key phrases to make sure the list has only unique values.
Keep in mind that the improvements discussed here are not as easy as they sound :) and are not comprehensive. Moreover, there are still issues around error handling. With that said, I suggest making sure your requirements are aligned with the complexity of the implementation you choose.
A Potential Savior
While working on the solution above, one alternative solution that came to my mind is much smoother and more comfortable. Still, it might be a little bit more costly and not as real-time as functions are, but it might provide better search capabilities on the resulting data set.
We can use Azure Cognitive Search, Key Phrase Extraction, and Text split cognitive skills to index documents and create an enriched knowledge base. However, incremental enrichment is in preview, and you might not need/want a cognitive search environment’s footprint. With that said, it is a straightforward implementation if you want to create an index with key phrases out of an archive of documents.
Hope this post gives you some ideas about different options and ways of using Text Analytics with large documents :) The source code of the project I built as a sample for this blog post is on Github. This is as far as we will go for now ;)
Resources
- AI enrichment in Azure Cognitive Search
- Data and rate limits for the Text Analytics API
- DurableTaskOptions.MaxConcurrentActivityFunctions Property
- Incremental enrichment and caching in Azure Cognitive Search
- Key Phrase Extraction cognitive skill
- Microsoft.Azure.WebJobs.Extensions.DurableTask Nuget Package
- Performance and scale in Durable Functions (Azure Functions)
- Text split cognitive skill
Daron Yondem advises senior technology leaders on AI-driven organizational transformation. Learn more →